There are three levels of analysis involved in the standardization of the various words of a name string. One result is the name’s standard form. This term refers to a correct and acceptable spelling. This and intermediate forms come out of and are related to a non-standard form called the variant or raw spelling. This latter term may refer to all forms whether considered correct and acceptable or not. In the process of developing standards every spelling is initially considered a standard until an expert declares it otherwise. At that time it is usually also evident how the spelling is used in the culture. This determines what the spelling’s assumed typical usage is until the expert declares it otherwise. The typical usage of a name piece includes its features of category, such as given name, surname, etc., and gender — the sex of the people who usually carry the name.
The words in a name string associate with one another in use. Some of them are functional words like van, von, de, etc., that associate with a surname. Others, such as certain pre-positive title phrases, consist of strings of words in their own right, such as the most honorable, the right reverend, her royal majesty, etc. If some simplifying assumptions are not made, the analysis of the constituents of the personal name string may become overly complicated. This will make for many types each possibly distinguished further by gender. To assure comparability between names we consider the name string constituency and try to understand the difference between the typical usage of the standard that has types and the usage of the various spellings that are often classed by an association with another word, such as, being derived from that word. Groups of standard forms may also be associated together in another level of standardization. Some of the more important derivations are handled in Chapter 3.
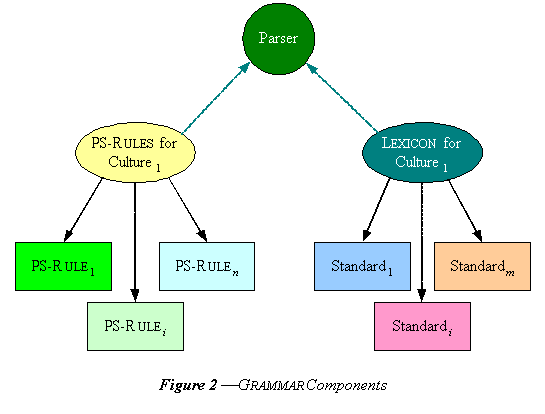
The analysis of names is described by a GRAMMAR and the central portion of a GRAMMAR are the phrase structure rules. These rules give the possible structures of name strings. The parser uses these rules in conjunction with a LEXICON, i.e., a knowledge base, to classify the pieces of the name string. The LEXICON is basically an indexed version of any word that may appear in name strings: 1) raw name pieces, 2) non-standard name pieces which are related to a particular standard as deviant versions, and 3) standard name pieces. The category symbols of the GRAMMAR are for classifying the pieces according to their typical usage. The parser checks each spelling in a string against the entries in the LEXICON. It is most efficient when it can find the word's categories of possible usage there. These category designations are the terminal categories of the GRAMMAR. In many cases, however, the category expected in the context of the string is not the typical usage of the corresponding form. So while the typical usage is the primary formal category, the rules must also make the parser aware of the secondary cultural usage options of the formal categories in the LEXICON.