
The kinds of variation among the spellings in a name group discussed above come in different degrees. To determine the amount of difference it is important to come up with a way to measure the change as a comparison is made between two spellings. Increased experience with calculating such measures will undoubtedly lead to a modification to the principles of name grouping listed above. One refinement is to reduce the distance between a name pair to the value of a function. A formalization of this idea takes each character (written symbol, c) as a primitive element, and each spelling (s as an arbitrary concatenation of some small number of characters. Each language imposes restrictions on the set of acceptible characters and which sequences might be allowable. Given two spellings (s) as parameters, an intuitive distance function ought to return the degree to which they differ from each other. Presumably the simplest expression would require that the difference (d) be expressed as a proportion (0 < d < 1.0) — a number between zero and one. If the measure is zero, there would be no difference, i.e., both items being compared would have the same identical spelling. Presumably the function would also be expected to yield one in the case where the two spellings are for different names. Perhaps it will also be advisable to consider a distance even greater than one, if, for example, their respective groups share no members. Secondly we will assume that there are some spellings of a name that are different from each other to a greater degree and some to a smaller degree. In this case presumably for each spelling there will always be some other which when compared yields some minimum non-zero difference.
The introduction to name variation paid attention to several phases or dimensions of the communication process that influence the name spelling. It seems reasonable, therefore, for the distance function to analyze the spelling along one of these four dimensions of comparison. An analysis whose fundamental elements are based on the written language alone has been called a graphological analysis and the fundamental units, the graphemes. The handwriting or typological style of the clerk may introduce ambiguity of interpretation, especially if the reader, viz. typist, is not fluent with it. An appropriate name for this dimension of analysis might be the iconic or optigraphic. In addition the choice of affix or other grammatical device may or may not affect whether the spelling exhibiting it belongs to the same name group as the spelling without it. This is a third or morphological dimension of analysis. The way the name itself is pronounced in the language is a third or phonological dimension. To remind us of these four dimensions of analysis, the following illustration is provided with selected distinctive fonts and colors on figure 51.
The bottom line on figure 51 illustrates that spellings are considered to be strings of characters concatenated together. However, it must be emphasized that concatenation may also be taken as a function that joins strings, each of which might be any number of characters. The way in which strings are analyzed into substrings and these in turn into other sub-substrings, etc. until they are analyzed as single-character strings, depends on the way the information contained in the string is seen as distributed into its various parts. The process of going from a particular spelling to some representation of that spelling in each dimension of analysis can be expressed using a function or a set of functions. In these higher dimensions, the elements of analysis are given their own symbolic variables to represent them. A grapheme is normally a single character or a particular set of characters originally chosen to represent a particular linguistic sound. The sounds of the language themselves are the phonemes (p). These are represented by placing certain symbols between forward slashes. The International Phonetic Alphabet provides a system whereby linguistic sounds may be represented by a certain set of special symbols. When more precise aticulatory precision is required, as when various accents of a language are contrasted, strings of these symbols, called phones (d) may be placed between square brackets. The science of linguistics also provides elements of meaning called morphemes (m). There is as yet no such thing as an “International Linguistic Ontology” for meaning, so these units are represented by normal spellings placed within curly brackets. (Parts of words are provided with n-dashes to designate the normal position of the stem to which they attach.) A possible term coined to refer to the distinctive images presented to the eye, the basic elements of a style of handwriting, is the iconemes (v). If a term is needed for the keys of a QWERTY keyboard, perhaps qwertemes would suit the need and the Currier font, the representation.
It is important to realize that each function or operation listed on figure 51 is just one of several possible. For example, the rendering of a particular character or string of characters as upper-case or as lower-case defines two separate functions. If a string of characters needs to be rendered in mixed case, i.e., certain letters capitalized, or proper case, i.e., initial letter capitalized, these are then further possible transliteration functions. Other renderings are also possible, For example, one abbreviation function normally takes the proper case rendering of a string as input and outputs the first syllable and a superscripted version of the final letter. There are numerous other versions of the abbreviation function in use. Various handwriting styles are in use for each of which kind there are also multiple functions. The output of these functions are in terms of iconemes and the best way to represent these units has not been very well developed. The strategy used here is to designate upper-case letters by their grapheme equivalent, adjacent minims with a superscripted “M,” ascenders with a superscripted “A,” and descenders with a superscripted “D.” Functions for coding strings of typewritten symbols use iconemes of a different sort, confusingly identical to other graphemes. These may be based on the QWERTY keyboard or be simply geminates or transpositions of keys. Each character or pair of characters has a different output for a particular input. Translating graphemes into morphemes or phonemes is much more complicated. This is done by utilizing a set of rewrite rules sufficiently diverse and selective to distinguish all the elementary units of the spoken language based on their spelling.
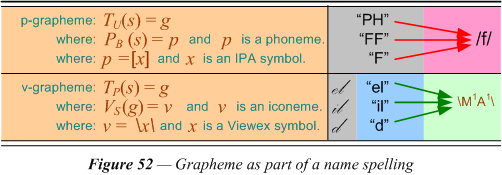
It should be clear from the foregoing that there are multiple uses of a “grapheme” as a unit of symbolic representation. One interpretation is as a variable to represent a raw spelling of a name as found in the data. It is also necessarily used as a variable to represent other kinds of elements for different dimensions of analysis. For these purposes the graphemes as symbols are best set off by special quotation marks, parentheses, or brackets. Two of these are illustrated in figure 52. The ones based on the phoneme /f/ are shown between forward slashes, which practice is customary in the field of phonetics. The p-grapheme has at least three forms with a function (P) to produce the phoneme from it. The inverse (P-1) of this function would yield any of the three graphemes when given the phoneme /f/. When there is ambiguity in the output of a function, it is no longer mathematically speaking a “function.” In an analogous fashion we set the iconeme between reverse slashes. The letter “M” stands for a single (indicated by the superscript) minim while the “A” represents a single ascender. These are just a few of the elements needed to describe spellings in the Viewex code for the Spencerian style of handwriting. The careful student should have noticed a transliteration function which is executed first on strings to produce a proper case string before it is ready for input into the Viewex function. As there is no conventional way of rendering Roman alphabets without the use of case, the translation into upper-case for input into the phoneme function is arbitrary but expedient. The Phondex function is theoretically executed on an unrendered raw string without case, for which there is no other graphemic representation.
Some of the relationships and algorithms proposed for calculating the distance between different spellings are listed in figure 11. The distances for which possible calculations might be tried are listed with labels corresponding to those placed on figures 7 – 9. We mentioned the importance of using relative frequency and length above. What is important is the magnitude of the change in these values that occurs in abbreviation or the differences between the spellings compared. At this point we can do little more than indicate the functions that must be taken into account and the rough magnitude of the resulting distances.

