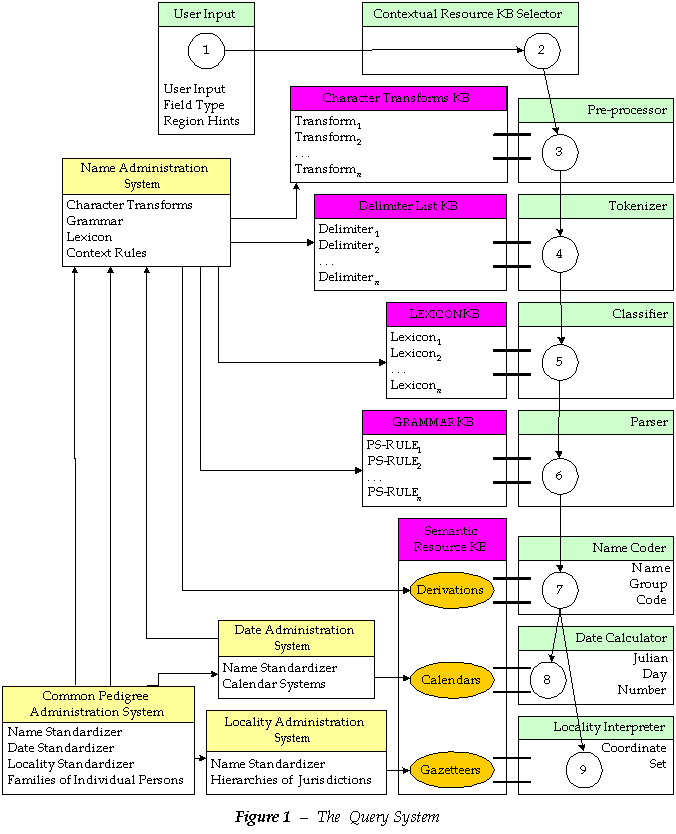
The query system is diagrammed in figure 1 below. The circled numbers give the flow of the standardization process, which takes an arbitrary spelling and finds which standard name has been assigned to it. The process of determining what the most appropriate grouping ought to be is performed by the use of the name administration system (NAS). The name administration system produces knowledge bases that plug into modules of the query system. These knowledge bases include 1) GRAMMARS, 2) LEXICONS, 3) character transforms, 4) delimiters, and 5) semantic resources. Other authority systems, notably the ones for places and dates, have administrative systems that allow NAS to manage the elements that belong to them that are names. Thus there are multiple sets of knowledge bases, not only for different regions (cultures), but for different kinds of names.
The diagram also includes an administrative system for the common pedigree. This is one system that uses an optimized version of the query system. Its domain is the data on individual persons who all have kinship relations to one another. The personal identifiers are their names and various kinds of vital events. The elements of historical events from which these are derived consist principally of places and dates. Other users of the system may make use of different sets of information relating to names, places, and dates.
This section covers the nine stages in the process of standardization that the query system realizes. The standardization is complete at stage seven for names, at stage eight for dates, and at stage nine for localities.
