| The independence assumption. The calculation of a record comparison weight as the sum of the weights of the field comparison weights relies on the assumption that the fields being weighted are independent (cf. ¶ 2-2.5, ¶ 4-1.4). The comparison space might be configured much as diagramed in figure 1 [NB: Within a field, agreement is still dependent on presence.] |
| This means that the probability of a comparison being a match would be directly proportional to the calculated agreement weight of each independent field. Consider the reliability and coincidence for the two fields in table 3 and see what weight they might contribute to a comparison. When the fields are independent we allow for the Given Name Code to agree even when the Sex is not the same. But in reality the Sex may be so reliable that the probability of this happening would be virtually zero. We say that the Sex depends on the Given Name Code. Another way of saying this is that the Given Name Code partitions the Sex. |
| FIELDPresence | Reliability & Coincidence |
W E I G H T S F O R C O M B I N A T I O N S (+ = agreement – = disagreement 0 = missing) | |||||||||
| p | r | c | + + | + – | + 0 | – + | – – | – 0 | 0 + | 0 – | 0 0 |
| Principal's Given Name Code 0.9679 |
0.9617 | 0.0250 | aw1 = +5.27 |
aw1 = +5.27 |
aw1 = +5.27 |
dw1 = –7.25 |
dw1 = –7.25 |
dw1 = –7.25 |
bw1 = 0.00 |
bw1 = 0.00 |
bw1 = 0.00 |
| Principal's Sex 1.0000 |
0.9932 | 0.5004 | aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
| Algorithm if Independent | 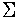 cw = cw = +6.26 |
cw = –0.93 |
cw = +5.27 |
cw = –6.26 |
cw = –13.5 |
cw = –7.25 |
cw = +0.99 |
cw = –6.20 |
cw = 0.00 | ||
| Conditional agreement. The agreement in field one is conditioned by agreement in field two. If the data in field two agrees, we know that the data in field one must agree. Some disagreement in field one is conditioned by the disagreement of field two, and some is not. Also the data must be present in field two before it can be present in field one. The relationships between the fields in the comparison space seems to be somewhat as diagramed in figure 2. |

The concentric circles illustrate the fact that P1 P2 and that A1 A2 P2 and that A1 A2 |
| Correcting for field value dependence. It appears that when field one depends on field two, we cannot simply multiply the individual probabilities of matching. When both fields agree or both disagree, the reliability and coincidence of field two are the only effective ones. It cannot happen that the dependent field agrees and the independent field disagrees. In case the independent field agrees and the dependent field disagrees, it seems that the fields would each contribute its own reliability and coincidence. This works because the presence is only involved in the disagreement weight and only the independent field can disagree on its own. The corrected comparison weights appear on table 4. |
| FIELD Presence |
Reliability & Coincidence |
W E I G H T S F O R C O M B I N A T I O N S (+ = agreement – = disagreement 0 = missing) | |||||||||
| p | r | c | + + | + – | + 0 | – + | – – | – 0 | 0 + | 0 – | 0 0 |
| Principal's Given Name Code 0.9679 |
0.9617 | 0.0250 | aw1 = +5.27 |
aw1 = +5.27 |
aw1 = +5.27 |
dw1 = –7.25 |
dw1 = –7.25 |
dw1 = –7.25 |
bw1 = 0.00 |
bw1 = 0.00 |
bw1 = 0.00 |
| Principal's Sex 1.0000 |
0.9932 | 0.5004 | aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
aw2 = +0.99 |
dw2 = –6.20 |
bw2 = 0.00 |
| Given Name Code depends on Sex |
cw = aw2 = +0.99 |
does not occur |
does not occur |
cw = –6.26 |
cw = dw2 = –6.20 |
does not occur |
cw = +0.99 |
cw = dw2 = –6.20 |
does not occur | ||
| Non-uniform partitioning. In our particular example there is another adjustment that coincidence requires. Sex is a large partition (about half). When we consider that there would be only masculine name forms with the Sex value "male," we would guess that the coincidence value would be very close to one in this new environment. This is approximately twice what it was for both sexes. However, a correct measure of coincidence does not divide and multiply with a lineal proportionality, so we cannot easily tell what it's actual value would be. Similarly the coincidence of the Given Name Code implies 32.36 equally sized partitions. But half of these are for male names and half are for female names. Here one might be tempted to double the value. However, the distribution of the names is not equal, and the effects of dividing the file in half are not in a lineal proportion on the coincidence value. Dividing the file cannot result in two files with implied equally sized partitions of 16.18. |
| Non-uniform standardization to multiple fields. Considering another example, suppose the investigator chooses to weight on Event Town. Each distinct town has a certain set of coordinates. This set of coordinates acts as a single locality code when taken together. It may well be that each distinct spelling for a town would be coded differently. This is not the case in reverse, however. A particular latitude or longitude could easily have several towns sharing that latitude or that longitude. Now suppose the investigator chooses to weight on Event Latitude and Event Longitude as two separate fields. This would give a weight based on independent reliability and coincidence values. Once the latitude is chosen, however, the choice of longitude is very much smaller than before. The actual coincidence value is certainly larger than the measured coincidence value, probably between one in three and one in ten. |
| Constructive value dependence. There is also an obvious value dependence among some of the personal name fields. Normally if we weight on the Name Code, we should not also weight on the name spelling. Spellings may be grouped as variants of a name and assigned their name group code on the basis of their spelling (usually by its outward form). After this grouping process the variation among spellings within those having a particular code may be great or small. The coincidence value of every name would measure differently, there likely being only a dozen or so name variations for each particular code. This process is quite different from calculating the coincidence value of a spelling as independent. In that case we simply estimate the independent probability of choosing the same spelling from among all the variations in the test database, not just those within a group. Constructive value dependence occurs when there is a full dependence of data values in one field on specific values in certain other fields. The field value's very presence is also dependent. |
| Another case of constructive value dependence arises when the meaning of the data in one field is a derivation of data in another field. For example, in genealogy, references to localities are to different jurisdictional levels, and each one may receive its code depending on its meaning. The town of Coos Bay in Oregon may be coded like Marshfield, an earlier name for the same town. This kind of grouping occurs with towns, counties, states, provinces, countries, etc., that may all be part of the locality designation identifying the place of the event. The town is only in one county, the county in one state, etc. The code, then, depends constructively on the locality. |
| Adjusting coincidence for value dependence. By way of illustration we will consider here a hypothetical situation where there are two levels of name codes, the second more general than, but based on, the first. Suppose that there are three value dependent fields: 1) actual spelling (A), 2) phonetic code (P), which would be constructed from the spelling, and 3) dialect code (D), which would be constructed from the phonetic code. Table 5 gives the various combinations of these fields that might be possible. For the sake of the discussion we will make up some coincidence values for agreement: for A, a = 0.0166; for P, p = 0.0250; and for D, d = 0.0412. The coding scheme creates a dependence chain with D dependent on P, and P dependent on A. Now, if the fields had been independent, it would be possible to estimate their joint coincidence values by taking the product of their individual values, as appropriate for the combination of fields present in the comparison. However, actual spellings that agree always have codes that agree. This means that certain agreement/disagreement combinations cannot occur. An asterisk marks the impossible combinations in the table. Notice the large discrepancy in the probability of agreement calculations with and without the assumption of independence. |
| Given name Combination of fields |
Calculation of Coincidental Agreement When Fields Are Independent |
Coincidence Assuming Independence |
Calculation of Coincidental Agreement When Fields Are Fully Dependent |
Coincidence Assuming Full Dependence |
| [ ] | ( 1 – d ) × ( 1 – p ) × ( 1 – a ) | 0.9193 | 1 – d | 0.9588 |
| [ A ]* | ( 1 – d ) × ( 1 – p ) | 0.9348 | ||
| [ P ]* | ( 1 – d ) × ( 1 – a ) | 0.9428 | ||
| [ D ] | ( 1 – p ) × ( 1 – a ) | 0.9588 | d – p | 0.0162 |
| [ P, A ]* | p × a | 0.0004 | ||
| [ D, A ]* | d × a | 0.0007 | ||
| [ D, P ] | d × p | 0.0010 | p – a | 0.0084 |
| [ D, P, A ] | d × p × a | 0.0000 | a | 0.0166 |
| Adjusting reliability for value dependence. Parallel with table 5 we might easily draw up a table for agreement in matched comparisons. Instead of coincidence the table would then be giving reliability. Value dependency requires adjustment to both the reliability and coincidence values. Suppose the fields being calculated are fully dependent so that field 1 depends on field 2, and field 2 depends on field 3. Now we need to look at a combination of fields and ask if their values might agree. If one of the fields agrees, say field 1, but not one of those it depends on, say 2 or 3, then the combination is impossible. |
| Generalizing the adjustment algorithm. As with presence dependence we may use subscripts for each combination so as to also refer directly to the length (n) of the dependency chain. So what we are saying is that we can use n to refer to the combination [ 1, 2, . . . , n ]. The adjusted reliability viz., coincidence for combination k is ark, viz., ack and there are k fields agreeing in combinations of fields in dependency chains of arbitrary length (n). We say that k = i, except where k = i = 0 when ro = 1, viz., co = 1, and where k = i = n+1 when rn+1 = 0, viz., cn+1 = 0. |
| ark = ri – ri+1 | (5.3) | ||
| ack = ci – ci+1 | (5.4) | ||
| FIELD Presence |
Reliability & Coincidence |
W E I G H T S F O R C O M B I N A T I O N S (+ = agreement – = disagreement 0 = missing) | |||||||||
| p | r | c | + + | + – | + 0 | – + | – – | – 0 | 0 + | 0 – | 0 0 |
| Principal's Given Name Code 0.9679 |
0.9617 ar1 = 0.1598 |
0.0250 ac1 = 0.0084 |
aw1 = +5.27 | aw1 = +5.27 aw3 = +4.17 |
aw1 = +5.27 |
dw1 = –7.25 |
dw1 = –7.25 |
dw1 = –7.25 |
bw1 = 0.00 |
bw1 = 0.00 |
bw1 = 0.00 |
| Principal's Given Name Spelling 0.9696 |
0.8019 ar2 = 0.8402 |
0.0166 ac2 = 0.9916 |
aw2 = +5.59 | dw2 = –2.31 dw3 = +0.24 |
bw2 = 0.00 |
aw2 = +5.59 |
dw2 = –2.31 |
bw2 = 0.00 |
aw2 = +5.59 |
dw2 = –2.31 |
bw2 = 0.00 |
| Given Name Code depends on Spelling |
0.8019 | 0.0166 | cw = aw2 = +5.59 |
cw3 = +3.93 |
does not occur |
does not occur |
cw = dw2 = –2.31 |
does not occur |
does not occur |
does not occur |
does not occur |
| Table 6 shows the effect on the record comparison weight when two fields are constructively dependent. Two comparisons are possible where only the spelling is important. In these cases using the adjusted reliability and coincidence (shown to left) is equivalent to considering only the spelling. In one case adjusted values are indispensable. The coincidence of spellings agreeing, when the code agrees is a very high value, i.e., this situation isn't much of a coincidence, particularly when the code partitions the spelling so finely. These adjustment values are more important when calculating the outcome probabilities. |
| A relatively innocuous variety of value dependence. Consider, for example, the differences that may occur in the day of the month field. The variability in the values that may occur in the day of month field depends naturally on the value in the month field. In five of the months the day of month may be any number from 1 to 31 (c = 0.0323), in six of the months the day of the month varies from 1 to 30 (c = 0.0333), and in one month it varies from 1 to 28 about three fourths of the time and 1 to 29 about one fourth of the time (c = 0.0354). One value in 31 and one value in 30, etc., does not have a very large impact on the coincidence value over all (c = 0.0331). |
| A more important variety of value dependence. The different jurisdictional levels of a locality derive from those below; each unit is defined as comprising certain units of the next lower level. This is another dependency between specific values. Each Country contains a certain number of Counties, each County contains a certain number of Clerical Districts and Towns, each CD and/or Town contains a certain number of Parishes, and each rural Parish contains a certain number of Farms. The specific jurisdictional units impose a particular coincidence value on each of its subordinates. The great variability from place to place makes it difficult to model this phenomenon at all accurately. |
| Other important instances of value dependence. By definition patronymic names tie the surname of the child to the given name of the father. Without detecting the different classes of surnames, the specialist has no option but to avoid choosing both fields for weighting. In many Western cultures there is naturally a high degree of dependence between the surname of a child and that of its father (both being the family name). Related to this is the fact that siblings have the same parents. If the parents' identifiers are used to identify individuals, there will be difficulty in distinguishing siblings from duplicates without the use of additional more unique identifiers. |