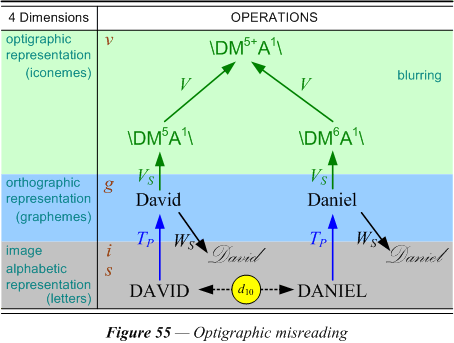
Optigraphic misreading. (V) The second respelling is what we might call optigraphic, a spelling based on a misreading of the name due to its appearance when written down on the page. Like mistyping, misreading is usually the last process of corruption that a name goes through, so one of the first to be detected. The same clerk who can mistype, can also misread, so it is conceivable that both errors might occur to the name being extracted. There are also at least two different levels of analysis that can describe some of the more obscure variations of this drastic kind of respelling. Figure 55 illustrates how to conceptualize the V-distance (d10) between two different names mistaken for each other by misreading.
The assumption is that the Spencerian writing style (WS) attempts to imitate the normal orthographic form of a name in a regular way. These rules are given by a direct equivalence transformation that reduces the forms of each letter to a linear sequence of basic elements: minims (M), ascenders (A), descenders (D), and both ascender and descender combinations (B). Such a simplification assumes that certain strokes of the pen (horizontal, dots) are fainter, blurred, or otherwise easily confused. There is presumably a further step of blurring that makes the count of identical adjacent elements to some degree uncertain.
Figure 56 shows how misreading can come about with an abbreviated name, which process also introduces its own degree of uncertainty. In this case the misreading has resulted in the interpretation of a form of Joseph as either Joshua or James, or even Josiah, three completely different names of the language. There are two different kinds of abbreviation illustrated in the figure: 1) conflation with two or three characters retained (AR), as when Jas. abbreviates James, and 2) truncation (AT), as when Josh. abbreviates Joshua. These are discussed in more detail in the section on abbreviation.
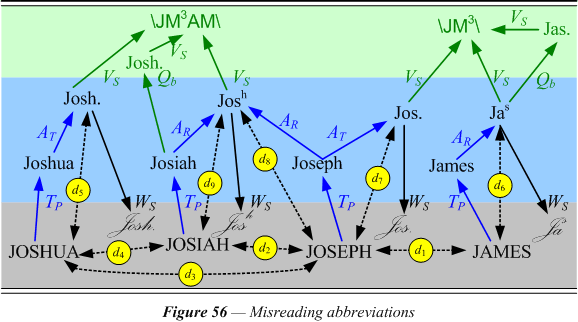
In calculating the distances between members of different groups, it is the possibility of confusion between them that is being taken into account. The confusions illustrated in figure 56 arise from the equivalence of their optigraphic representations. Of the many parameters that play into the effects of an abbreviation function, the two most important seem to be: 1) the frequency of occurrence of the abbreviation over against that of the full spelling (f), and 2) the ratio of the change in length (l), which expresses the space savings that is achieved by abbreviating. The two abbreviation functions handle these parameters of relative frequency and relative length differently.
Optigraphic misreading is similar to typographical misspelling in that the relative frequency of occurrence of a such a variant can be an indicator that it is an error. Consider the case when the interpretation of the written image is unique, i.e. the spelling does not occur more than once. Suppose, for example, that Leffebvre, is written using a French italic hand so that its VIEWEX code becomes \LMB2MA5\. In this style an upper case F is written by the use of two lower case F’s. This image has in fact been interpreted as Leslebore, \LMBAMA5\. Suppose further that this latter spelling has no other occurrences — only the one instance has ever been seen. It does not take much blurring for the two VIEWEX codes to be taken as equivalent. As with misspelling, the score assigned to this reading must take into account the drastic difference between the relative frequencies and particularly that the one spelling is unique. The principle followed in this strategy is that a unique spelling ought to be reinterpreted as a reading variant (or typo) of its nearest more common spelling.
Because there may be complications, such as abbreviations, that alter the frequency, is it appropriate to find reading variants of more common spellings. Unlike the table of QWERTY keystroke alternates, the VIEWEX code is designed for full string comparisons. The strategy of using this code may be quite different from the one used for finding Q-variants. This code identifies V-variants in the same way that SOUNDEX and PHONDEX find their matches. Generative rewrite rules are followed to provide all candidate spellings with a code which is then compared as being the same or different. It may be possible, however, to execute an edit-distance function on codes that exhibit partial agreement, so as to allow for the effects of some additional blurring of the image coded. Care would have to be taken to prevent too much blurr, as then excessive serendipidous matches might become evident. As with typos, it is important to mark V-variants as such, if they are to be included in the name group.
The V-variant has a distance from each of the standards to which it belongs that marks it as more or less likely to be perceived as such. On figure 56 the distance d6 of an abbreviation in the JAMES group and d7 in the JOSEPH group share the same V-code which can be compared to distinguish the spelling as a more or less likely variant of one than of the other. Similarly there is a distance d8 of an abbreviation in the JOSEPH group and d9 in the JOSIAH group are derived by the same two functions, but with different relative frequencies. Its V-variants are typographically and abbreviatorily different, but only one is marked with its distance d5 from JOSHUA. The unmarked one, the typographical alternative, may be indistinguishable without recourse to the image. The result is that its frequency would interfere with an accurate measure of the frequency of the other. In this case there is no way to mark the V-variant in the group with a helpful frequency for use in making a match decision.
