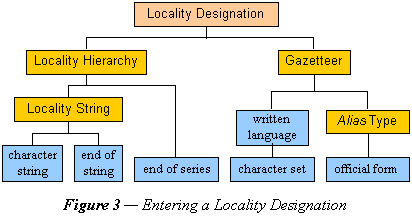
1.1 User Input. The first stage in the pipeline leading to standardization yields the name string along with information about its language or cultural identity. The user or application inputs the character string that represents or helps identify the particular entity being sought. The format may well yield other information, such as, what type of name it is or what kind of entity is being referred to by it. For example, in the census of Canada in 1881, the Native American version of the name of individuals is written as syllables separated by hyphens. Sometimes the English interpretive version of the native name is given. These may be two aliases for the same person. It is also possible that the user give hints to his own or the data’s locale by the choice of keyboard character set (code page). For example, if the string is composed of logographic symbols from Korean, the input module may infer the likely language and culture. When such hints are available and by these and other means the culture is determinable, it is then possible to specify the set of knowledge bases by which to analyze the name further. Figure 1 diagrams some of the elements of the proper name structure required to maintain this information.
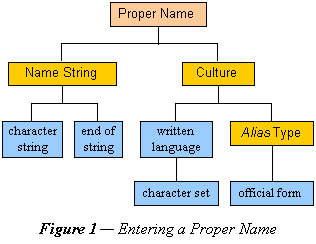
The entry of a calendar date is similar to that of proper names. In this case correct interpretation depends on knowledge of the calendar used by the culture.
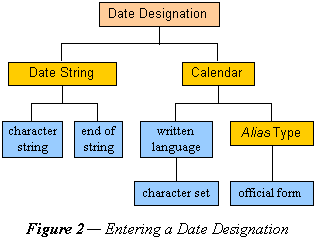
The main difference in the entry of a locality is that each locality in a series or hierarchy is named. In this case correct interpretation depends on knowledge contained in a gazetteer of the world.