
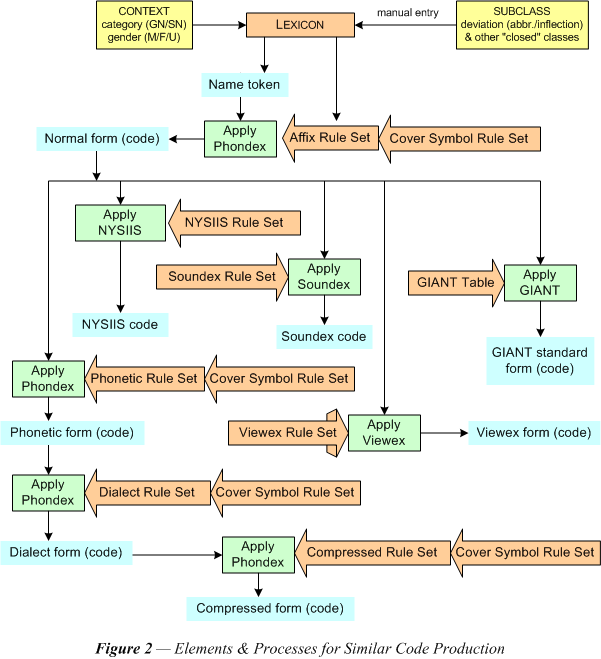
Similar code production rules describe how spelling differences can be ascribed to different dimensions of similarity. The raw material going into the LEXICON is the same as in a resource file to the data of which personal record linkage system specialists need to apply standards. There were three sets of rules necessary in analyzing name strings to provide for many of the entries in the LEXICON. These were the rules of 1) the pre-processor, 2) the tokenizer, and 3) the classifier. The size of the LEXICON can be reduced considerably in many cultures by analyzing out forms that commonly occur in many names. Figure 1 illustrates some of these common elements. There are the common orthographic conventions that are largely handled by the pre-processor and tokenizer. The LEXICON also contains all members of closed classes often known as "stop-words." These elements must be recognized by the parser. The names themselves, commonly classed as given names and surnames, are open classes. These are members of name groups; these are also the members of similarity groups that are brought together by rules like the Phondex rules.
Many languages have syllables or other phonetic elements that are attached to names as prefixes or suffixes and which carry a more or less characteristic meaning. Affix rules are for separating such combining forms from the name stem. The same stem may often appear with or without various of these affixes, so that removing them further reduces the size of the LEXICON. Their identity must often still be retained for comparison purposes, however, since they may carry distinguishing information about the individual, such as the gender or marital status. The lexical entries for affixes provide this kind of semantic content.
In general there are two kinds of rule sets that will generate similarity codes: tables and production rules. The GIANT table has an entry for each spelling and assigns a particular arbitrary code to the members of each name group. Each table entry matches a variant spelling to a standard spelling, which in effect is the GIANT “code.” The production rules generate a new spelling based on the original spelling, or some part of it. This is the principle behind the rule sets for Soundex, NYSIIS, Viewex, and Phondex rules. All rules are ordered within their set so that the earlier rules express the more general grouping principles and have a wider degree of application than the later rules. The output of one rule becomes the input to the next rule. Unlike the others, Phondex consists of three serially ordered sets with useful output at each level. The rule sets defined for Soundex and NYSIIS are fixed generating algorithms so that they cannot be changed or updated.
In stark contrast to the above codes, which are designed to classify names into groupings, there are various string comparators. These are algorithms (cf. Jaro string comparator) that are designed to take two strings and calculate a measure of similarity between them. Like production rules their algorithms are fixed, but they do not produce a representation that can be associated with a particular spelling.
Similar code production rules are for describing how spelling differences may possibly be ascribed to different dimensions of similarity. Each rule consists in four distinct elements for qualifying their input and specifying their output. In general they all specify 1) the original character string to be interpreted (OLD) and 2) the character string it is to be treated as equivalent to (NEW). There may also be elements to give conditions or contextual restrictions to further qualify the input. To specify these elements there are cover symbols that must be defined.
